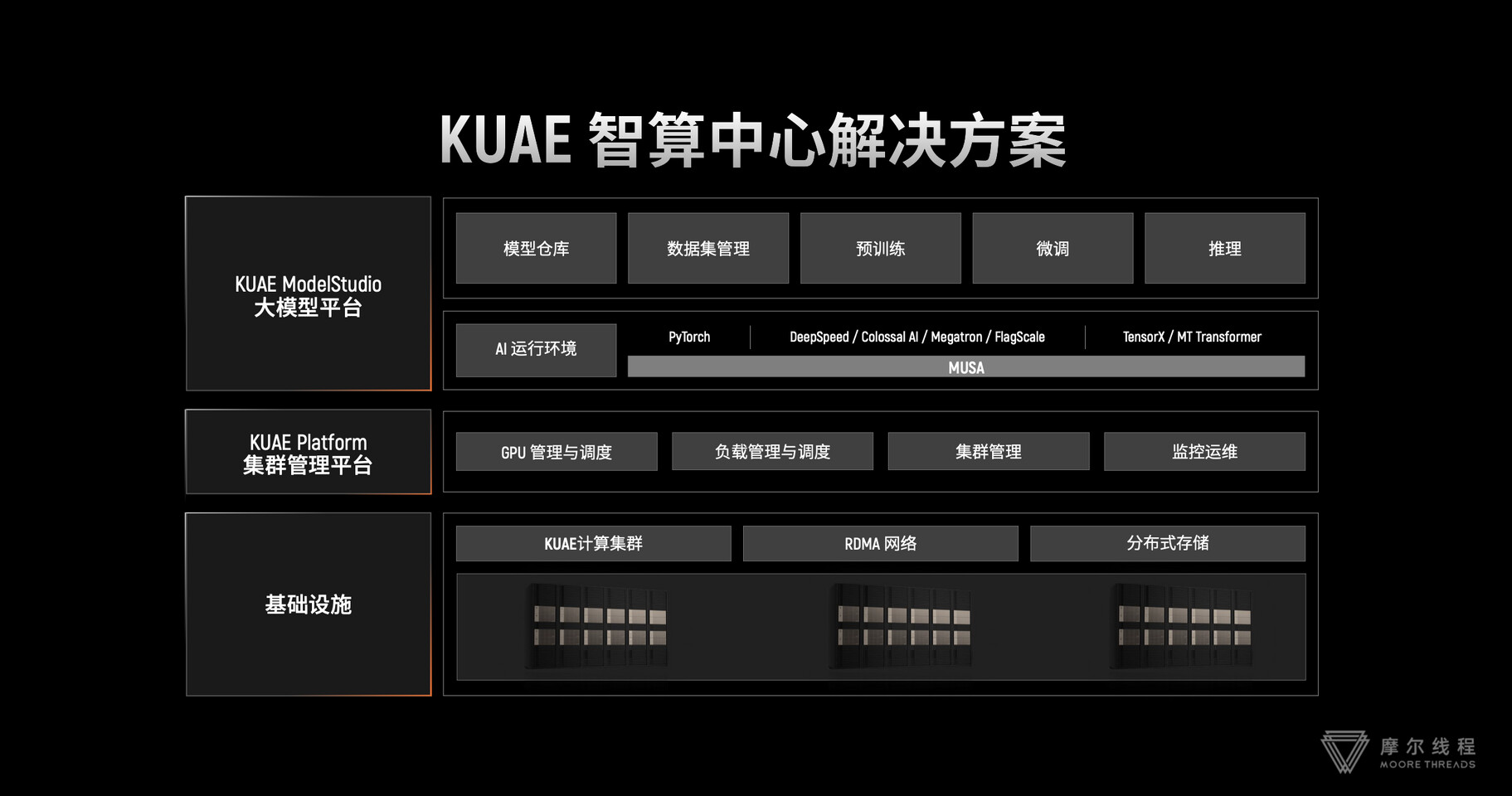
Chinese chipmaker Moore Threads has introduced its first domestically-produced AI training cluster, called the KUAE Intelligent Computing Center, which consists of a 1000-card setup. The cluster's main component is Moore Threads' new MTT S4000 accelerator card, equipped with 48 GB VRAM and utilizing the company's third-generation MUSA GPU architecture and 768 GB/s memory bandwidth. The card can achieve 25 TeraFLOPS in FP32, 50 TeraFLOPS in TF32, and up to 200 TeraFLOPS in FP16/BF16. It also supports INT8 at 200 TOPS. The MTT S4000 is designed for both training and inference, utilizing Moore Thread's high-speed MTLink 1.0 intra-system interconnect to scale cards for distributed model parallel training of datasets with hundreds of billions of parameters. Additionally, the card provides graphics, video encoding/decoding, and 8K display capabilities for graphics workloads. Moore Thread's KUAE cluster combines the S4000 GPU hardware with RDMA networking, distributed storage, and integrated cluster management software. The KUAE Platform oversees multi-datacenter resource allocation and monitoring, while KUAE ModelStudio hosts training frameworks and model repositories to streamline development.
With its integrated solutions already proven on thousands of GPUs, Moore Thread is well-positioned to power a wide range of intelligent applications, from scientific computing to the metaverse. The KUAE cluster reportedly achieves near-linear 91% scaling. For example, when using 200 billion training data, Zhiyuan Research Institute's Aquila2 with 70 billion parameters can complete training in 33 days, while a model with 130 billion parameters can complete training in 56 days on the KUAE cluster. Furthermore, the Moore Threads KUAE killocard cluster supports long-term continuous and stable operation, breakpoint resume training, and has an asynchronous checkpoint that takes less than 2 minutes. In terms of software, Moore Threads ensures full compatibility with NVIDIA's CUDA framework, and its MUSIFY tool translates CUDA code to MUSA GPU architecture with no performance penalty.